Visual Med-Alpaca: A Parameter-Efficient Biomedical LLM with Visual Capabilities
| Chang Shu1* | Baian Chen2* | Fangyu Liu1 | Zihao Fu1 | Ehsan Shareghi 3 | Nigel Collier1 |
| 1University of Cambridge 2Ruiping Health 3Monash University |
Demo
Overview
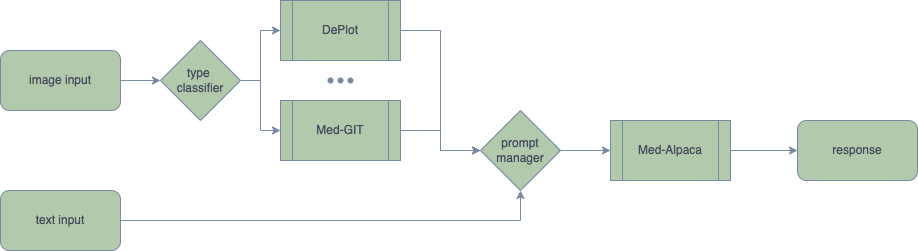
Domain-specific foundation models play a critical role in the biomedical field, as the language used in biomedical texts is highly specialized, often encompassing domain-specific concepts and relationships not found in general domain text corpora such as Wikipedia and Books. Empirical evidence demonstrates that pretraining on substantial amounts of biomedical text significantly improves language models' performance on various biomedical text mining tasks, as compared to existing publicly available pretrained language models (PLMs) (Lee et al., 2019; Gururangan et al., 2020, Gu et al., 2021). Modern large language models (LLMs) necessitate an unprecedented level of computational resources for full-model fine-tuning. The cost of fine-tuning even a 7-billion-parameter LLM exclusively on PubMed is prohibitively expensive for the majority of academic institutions. Pretraining models on extensive medical image datasets to attain multimodal capabilities incurs even higher costs. Consequently, researchers are exploring more cost-effective techniques such as Adapter, Instruct-Tuning, and Prompt Augmentation to develop models that can be trained and deployed on consumer-level graphics cards while maintaining adequate performance. In the context of bridging text and vision for multimodal applications, training can also be similarly expensive (Alayrac et al., 2022). Besides, to the best of our knowledge, there is no publicly available multimodal generative foundation model specifically designed for biomedical applications. In response to these challenges, we introduce Visual Med-Alpaca, an open-source, parameter-efficient biomedical foundation model that features a plug-and-play visual extension framework. To develop the Visual Med-Alpaca model, we initially create a biomedical instruction set by extracting medical questions from various medical datasets within the BigBIO repository (Fries et al., 2022). Subsequently, we prompt GPT-3.5-Turbo to synthesize answers for these questions. Multiple rounds of human filtering and editing are performed to refine the question-answer pairs, resulting in a high-quality instruction set comprising 54k data points. Next, we expand Med-Alpaca into Visual Med-Alpaca by connecting the textual model with "visual medical experts," which are specialized medical computer vision models. For instance, in radiology-domain applications, we train an in-house radiology image captioning model called Med-GIT (see later for details). When given an input image, a classifier determines if or which medical visual expert is responsible for the image. The designated medical expert then converts the image into a text prompt. The prompt manager subsequently merges the converted visual information with the textual query, enabling Med-Alpaca to generate an appropriate response. Ongoing work. A paramount objective for the future is to thoroughly assess the medical proficiency and potential shortcomings of Visual Med-Alpaca, encompassing issues such as misleading medical advice and incorrect medical information. Moving beyond traditional benchmarking and manual evaluation methods, we aim to focus on different user groups, including doctors and patients, and evaluate all facets of the model through a user-centered approach. This comprehensive assessment will enable us to ensure the reliability and effectiveness of Visual Med-Alpaca in addressing various biomedical tasks and catering to the diverse needs of its users. It is also important to note that Visual Med-Alpaca is strictly intended for academic research purposes and not legally approved for medical use in any country.
Model Architecture and Training Pipeline
Domain Adaptation: Self-Instruct in Biomedical Domain
The process of collecting inquiries from various medical question-and-answer datasets (MEDIQA RQE, MedQA, MedDialog, MEDIQA QA, PubMedQA) is implemented in our study. This approach aims to increase the diversity and thoroughness of the dataset and improve the accuracy and comprehensiveness of the obtained results. We synthesize answers of these questions with GPT-3.5-Turbo in the self-instruct fashion. The GPT-3.5-Turbo model is equipped with advanced natural language processing capabilities that enable it to understand and generate human-like responses to a wide range of questions. This makes it a reliable tool for generating structural and informative answers. The process of filtering and editing question-answer pairs was performed manually. A total of 54,000 turns were carefully selected, taking into account the criteria of balance and diversity.
Visual Adaptation: Radiology Image Captioning, Deplot, and More
Visual input constitutes a vital component of the medical domain, supplying indispensable information in healthcare environments. Healthcare professionals extensively depend on visual cues for diagnosis, monitoring, and treatment of patients. Medical imaging technologies, such as X-rays, CT scans, and MRIs, offer unparalleled insight into internal organs, detecting diseases and abnormalities that may be invisible to the naked eye. Additionally, scientific figures and medical records, including plots, charts, and tables, are prevalent in the medical field. We propose linking visual experts with Med-Alpaca, as foundation model chaining presents a modular and highly adaptable framework for incorporating a diverse array of visual modules. Within this framework, any multimodal task can be divided into two essential stages: (1) the conversion of images to text, and (2) cognitive reasoning based on the derived text. In our context, visual experts (i.e., visual foundation models) transform medical images into an intermediate text representation. This converted data is then used to prompt a pretrained LLM, leveraging the inherent few-shot reasoning capabilities of LLMs to generate appropriate responses. Currently, our platform supports two distinct visual experts: Med-GIT and DePlot, chosen due to the widespread presence of radiology images and plots within the medical domain. The system's architecture is also designed to enable seamless integration of alternative medical visual experts, and we plan to incorporate additional medical visual foundation models as visual experts in the near future. The Med-GIT model represents a GIT: Generative Image-to-text Transformer for Vision and Language, fine-tuned specifically on the ROCO dataset to facilitate specialized radiology image captioning. The training procedure for the model is outlined in comprehensive detail in our publicly accessible Github repository.
Case Study
Input 1: What are the chemicals that treat hair loss?
OTHER METHODS
Input 2: What is seen in the X-ray and what should be done? 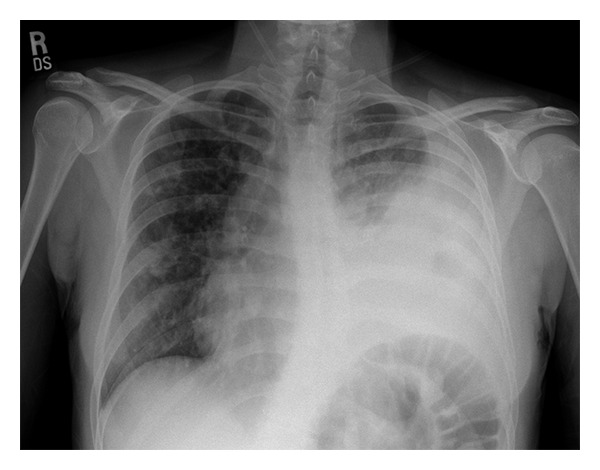
OTHER METHODS
Input 3: How effective is this treatment on papule? 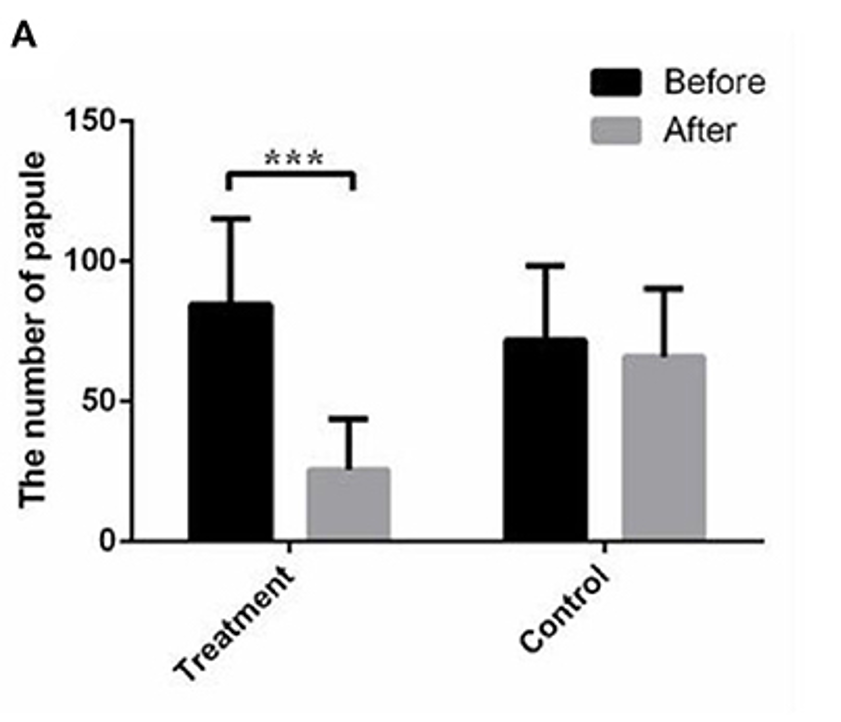
OTHER METHODS
Future Work
One of the most crucial ongoing works is the systematic evaluation of Visual Med-Alpaca, as well as other NLP models within the biomedical field. With the varying structure and type of medical data, it is essential to assess the efficacy of NLP models and their generalizability across different datasets. We also expect pretraining on medical data can enhance the performance of NLP models in the biomedical field. It should help in the identification and reasoning of disease phenotypes, drug mechanism and the representation of clinical concepts. The addition of genome protein modality may also help in achieving better reasoning in LLMs. Given that genetic and protein information are critical for understanding disease processes, LLMs can aid in the analysis of large volumes of genomic data, making it possible to identify novel mutations involved in various disease processes. Therefore, incorporating genomic information into LLMs will enable a wider range of applications within the biomedical field.
Implementation Details
We follow the hyper-parameters as reported in the Github repo of Alpaca-LoRA and Alpaca:
Disclaimers
Visual Med-Alpaca, is intended for academic research purposes only. Any commercial or clinical use of the model is strictly prohibited. This decision is based on the License Agreement inherited from LLaMA, on which the model is built. Additionally, Visual Med-Alpaca is not legally approved for medical use in any country. Users should be aware of the model's limitations in terms of medical knowledge and the possibility of misinformation. Therefore, any reliance on Visual Med-Alpaca for medical decision-making is at the user's own risk. Note: The developers and owners of the model, the Language Technology Lab at Cambridge University, do not assume any liability for the accuracy or completeness of the information provided by Visual Med-Alpaca, nor will they be responsible for any potential harm caused by the misuse of the model.
Acknowledgement
We are deeply grateful for the contributions made by open-source projects:
LLaMA,
Stanford Alpaca,
Alpaca-LoRA,
Deplot,
BigBio,
ROCO,
Visual-ChatGPT,
GenerativeImage2Text.
|
